 Normale Erfassung
Normale Erfassung
 Dauermonitoring
Dauermonitoring
 Gondelmonitoring
Gondelmonitoring
 Normale Erfassung
Normale Erfassung


Die Wundertüte Künstliche Intelligenz
In beinahe allen unserer Arbeitsprozesse am Computer spielt heute KI eine Rolle. Sie wurde vielleicht genutzt, um ein Programm zu schreiben, mit dem Sie arbeiten. Sie schlägt uns Textabsätze vor. Sie wertet nicht nur unsere Daten aus, sie schlägt uns vielleicht sogar schon vor, was die Daten aussagen. Sie wird als der Heilsbringer in vielen Bereichen des Artenschutzes angesehen. Sie soll Arbeit sparen und die Auswertungen viel schneller und besser als ein Mensch durchführen. Kann sie das? Und was ist nun KI in diesem Kontext genau? Und ist sie wirklich neu? Es gibt sehr viele Fragen, und leider all zu selten Antworten. Künstliche Intelligenz kann dabei sehr unterschiedlich gestaltet sein. Ob nun Sprachmodelle für die Analyse von Texten (das ist wohl die häufigste Anwendung), Bilderkennung, Tonerkennung, Mustererkennung oder generische KI zur Erzeugung von Daten. Insbesondere letztere begegnet uns im Alltag heute in Form bunter KI-Illustrationen, ohne die wir bis vor kurzem bestens ausgekommen sind, oder durch deep-fakes, mit denen Verleumdung und Betrug betrieben wird. Also ist KI in der Anwendung definitiv nicht immer nur etwas positives.
Künstliche Intelligenz ist, wie beschrieben, ein weites Feld. Wir setzen bereits seit 2005 machine learning ein, dabei handelt es sich um ein Teilbereich der künstlichen Intelligenz. Als langjähriger ecoObs-Kunde und Anwender von bcDiscriminator, batIdent oder heute CoreML arbeiten Sie also unter Umständen schon seit 2006 mit einem KI-Werkzeug, ohne es zu wissen. Bis heute ist das von uns gewählte Verfahren randomForest ein beliebtes und leistungsfähiges Werkzeug. Denn es ist relativ wenig anfällig für das sogenannte overfitting und generalisiert relativ gut für unbekannte Daten. Beides ist bei der Unterscheidung von Fledermausrufen aus Habitataufnahmen hilfreich.
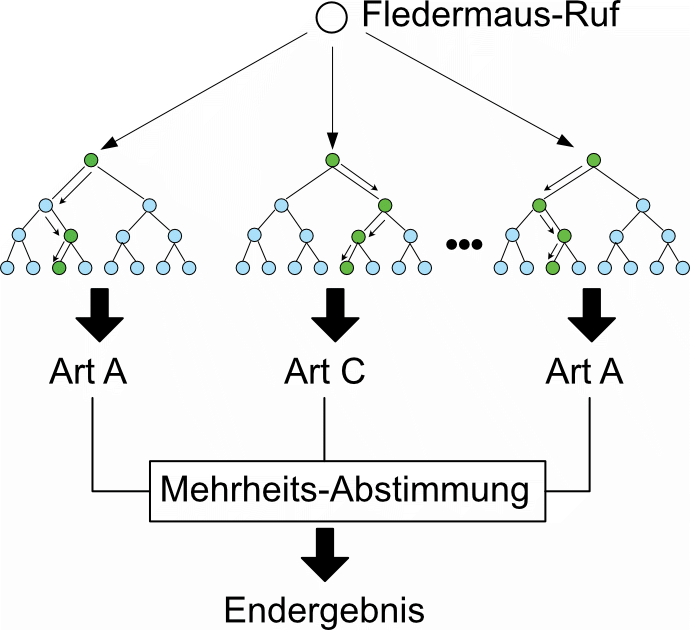
Bild-basierte KI
Machine learning mit randomForest setzt tabellarische Zahlen-Daten voraus. Wir haben für die Ermittlung von Rufmesswerten vor über 20 Jahren einen bahnbrechenden Algorithmus entwickelt, mit Hilfe dessen solche Werte ermittelt werden. Wird heute mit KI im Rahmen von Fledermausruferkennung oder -bestimmung geworben, dann handelt es sich dabei beinahe ausschliesslich um Bild-gestützte KI-Verfahren. Dazu werden Sonagramme berechnet und für die KI verwendet. Auch wir nutzten das seit 2020 und haben dazu bereits einen Wissensartikel über das Problem geeigneter Sonagramme verfasst. Im Folgenden gehen wir etwas mehr auf den Vorgang des Trainings und Selbstlernens ein. Wir hoffen, dass Sie am Ende dieses Beitrags etwas besser verstehen, wieso oder wann eine Sonagramm-basierte KI geeignet ist und wie die Ergebnisse eingeordnet werden können. Dazu tauchen wir in die Tiefe des Lernens ab - deep learning.
Deep machine learning
Am Beispiel der Erkennung von Ereignissen wie zum Beispiel feeding buzz oder Sozialruf betrachten wir das Vorgehen, das ein KI-Training und Verfahren zur Erkennung von solchen Ereignissen in Sonagrammen nutzt. Zur Objekt-Erkennung - wir betrachten den Fledermausruf als Objekt in einem Foto - gibt es diverse Verfahren wie z.B. YOLO, Faster-RCNN oder TransferLearning von Apple. Zwar haben die Verfahren teils deutliche Unterschiede in der Bildverarbeitung oder dem Aufbau des lernenden Netzwerks, jedoch ist das generelle Vorgehen immer das selbe. Es wird ein neuronales, selbstlernendes Netzwerk verwendet. Solche Netzwerke sind die Basis für viele der modernen Bild-Erkennungs-Methoden. Die Netzwerke bestehen aus verschiedenen Ebenen. Die Eingangsebene, die verborgene Ebene (das eigentliche neuronale Netzwerk) und die Ausgangsebene. Es handelt sich dabei um einzelne Neuronen (oder Layer), die den Datenstrom verarbeiten und aus den Eingangsmustern selbstständig Merkmale ableiten, um komplexe Muster zu erkennen. Jedes Neuron hat dabei je Eingangssignal eine Gewichtung und einen internen Bias, das Ausgangssignal wird mittels einer sigmodialen Funktion ermittelt (im Bild weggelassen, da es sonst zu unleserlich wird). Das bedeutet, der Eingangswert wird mit einer sigmoidalen Funktion zusammen mit Gewichtung und Bias in eine Antwort umgerechnet, die graduell zwischen 0 und 1 ausfällt. Dies erleichtert das Lernen enorm, da sich bei Änderungen der Gewichtung oder des Bias nicht ein plötzliches "Kippen" des Ausgangs zwischen 0/1 ergibt, sondern eben eine gemässigte Reaktion im Bereich von 0 bis 1.
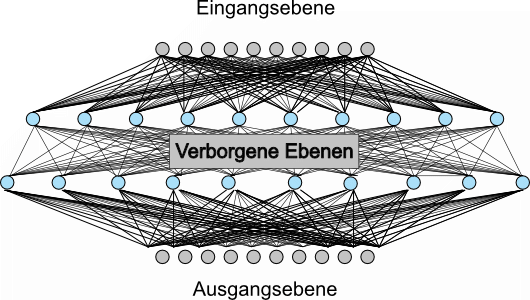
Für den Prozess des selbstständigen Lernens werden nun Eingaben gemacht, deren Ergebnis bekannt ist. Also zum Beispiel wird ein Ruf vorgegeben und dessen Art als Ergebnis angegeben. Das Netzwerk beginnt nun mit Feedback-Routinen (Gradientenabstieg), die Gewichtungen und Biases jedes Neurons so anzupassen, dass am Ende das gewünschte Ergebnis erscheint. Die Verlustfunktion (loss) wird so minimiert. Das bedeutet, das Ergebnis des Netzwerks wird mit dem gewünschtem Zielwert verglichen. Der sich daraus ergebende Fehler wird dann wieder rückwärts durch das Netzwerk zurückgeleitet, dabei wird berechnet, welchen Fehleranteil jedes einzelne Neuron hat. Nun werden die Gewichtungen und Biases so verändert, dass der Fehler verringert wird.
So wird für jeden weiteren Ruf im Trainingsdatensatz verfahren. Am Ende stehen dann je Neuron Gewichtungen und Biases zur Verfügung, die die Erkennung möglichst korrekt durchführen. Das ist ein relativ komplexer Prozess, bedenkt man, dass die neuronalen Netzwerke auch bis zu 1000 Neuronen, organisiert in Layern, aufweisen können. Bei der Verarbeitung von Bildern kommen in der Regel keine reinen neuronalen Netze zum Einsatz, sondern sogenannte CNN, die Convolutions-Filter vor das Netzwerk schalten. Das bedeutet einfach, es gibt vorne weg Ebenen, die durch mathematische Verfahren zum Beispiel Kanten im Bild ermitteln. Das geschieht mittels Kernel-Funktionen, die über die Rohdatenmatrix des Bildes gleiten. Solche Netzwerktopografien können am Ende mehrere Millionen Parameter beinhalten, über die sie definiert sind.
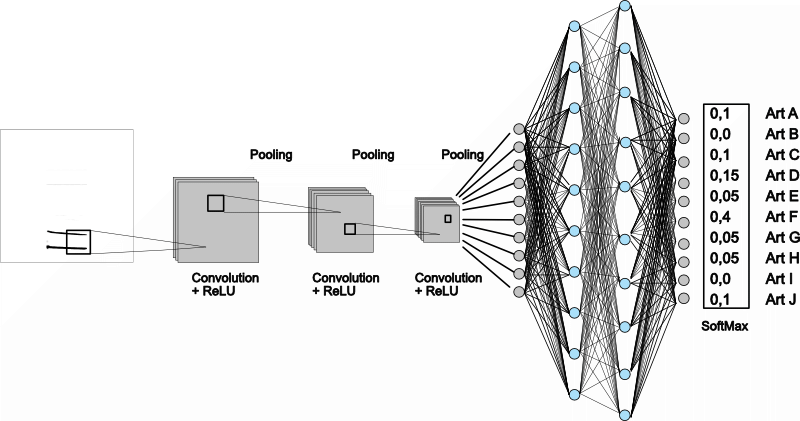
Der gesamte Lernprozess läuft im Verborgenen ab. Beim Training hat man einzig die Möglichkeit, eine initiale Lernrate zu wählen, sowie den Algorithmus für die Optimierung zu definieren. Welche Eigenschaften des Eingangsbildes am Ende für die Bildung des Ergebnisses relevant sind, ist nicht deterministisch. Verschiedene Trainingsläufe können andere relevante Bildanteile ergeben. Dies liegt daran, dass die initiale Besetzung der internen Parameter des Netzwerks und jeden Neurons zufällig erfolgt.
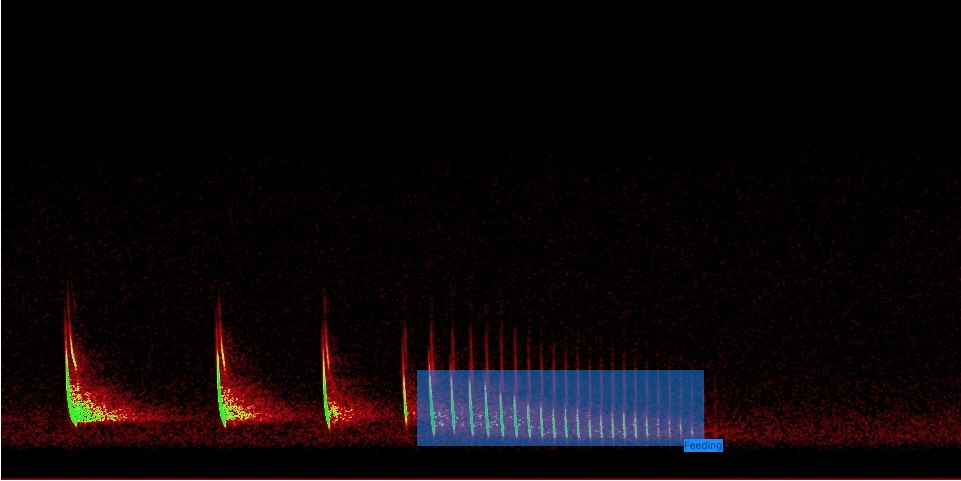
Am Beispiel der Objekt-Detektion, die solche Netzwerke verwendet, möchte ich zeigen, welche Probleme durch das Selbstlernen auftreten können. Das Netzwerk lernt basierend auf einer Vielzahl von Bildern, die speziell für das Training gesammelt wurden. Dabei handelt es sich um Sonagramme von Tonaufnahmen, die im Beispiel feeding-buzz Laute enthalten. Im Bild wird der entsprechende Bildteil mit dem feeding-buzz markiert. Weiterhin erzeugt man ebenso einen Validierungsdatensatz, der im Idealfall aus Sonagrammen unabhängiger Aufnahmen besteht. Diese Arbeitsschritte sind heute nicht mehr nur Spezialisten vorbehalten. Im Prinzip kann diese jeder auch selber mit frei verfügbaren Tools durchführen.
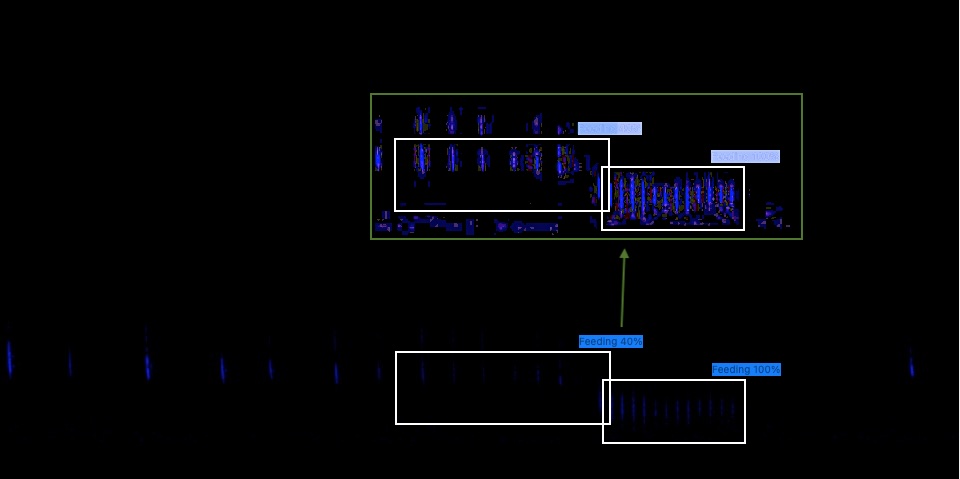
Die Leistung solch eines relativ gut trainierten Werkzeugs ist auf den ersten Blick wirklich erstaunlich. Selbst in leisen Aufnahmen werden beinahe unsichtbare feeding-buzz Elemente gefunden. Da freut sich der KI-Anfänger, aber auch der Fortgeschrittene. Nur, wenn man versteht, was da bei der Convolution passiert und wenn man dann beginnt, systematisch den Algorithmus zu testen, dann merkt man schnell eines: das Training hat etwas gelernt, das aber auch anderswo, zum Beispiel im zufälligen Rauschen, auftaucht. Denn was passiert bei der Verarbeitung des Bildes? Durch die dem Netzwerk vorgeschaltet Verarbeitung wird das Bild teils drastisch verändert. Es werden zum Beispiel Normalisierungen vorgenommen. Tools, mit denen man sonst schlechte Fotos verbessert.

Das bedeutet, der KI-Erkennungs-Detektor kann sehr sensitiv auf andere Sonagramme reagieren. Selbst wenn kontrolliert wird, dass immer die identischen Einstellungen verwendet werden, wirken sich Unterschiede des Detektors, Mikrofons und der Aufnahmeumgebung unter Umständen drastisch aus. Es handelt sich um Faktoren, die ohne manuelle Kontrolle und Sonagramm-Anpassung nicht automatisch korrigiert werden können. Der Urheber eines solchen Werkzeugs kann kaum alle möglichen Aufnahmesituationen und Geräte beim Training des Algorithmus mit berücksichtigen. Spätestens neue Geräte werden im schlimmsten Fall gänzlich andere Charakteristiken in den Aufnahmen aufweisen. Für den Anwender bedeutet dies dann aber auch, dass beim Einsatz unterschiedlicher Geräte Ergebnisse alleine deswegen voneinander abweichen können. Die meisten Detektor-Hersteller wechseln regelmässig die Mikrofone oder das gesamte Geräteverhalten. Eine hohe Produktupdaterate kann dann zum Beispiel immer wieder Anpassungen solch einer KI nötig machen.
Unseres Wissens nach ist ecoObs momentan der einzige Hersteller, der seit über 20 Jahren gleichbleibende Aufnahmequalität garantiert und mit Ausnahme eines leicht verminderten Rauschens bewußt die Charakteristik nicht verändert. Das bedeutet nicht nur das selbe Mikrofon, sondern eben auch sehr ähnliche analoge Schaltungen, um eine Konstanz in der Aufnahmequalität zu haben. So konnten wir mit dem von uns entwickelten feeding-buzz Detektor tatsächlich selbst die Aufnahmen des batcorder-Prototyps von 2004 noch relativ unproblematisch untersuchen. Und dennoch wird bei ungünstigem Aufbau und der Anwesenheit von Heuschrecken dennoch die Erkennungs-Sicherheit durch falsch positive Signale leiden.
Sollten wir Ihr Interesse geweckt haben sich weiter mit neuronalen Netzen für die Bilderkennung zu beschäftigen, dann empfehlen wir Ihnen die beiden folgenden Lektüren, sie beinhalten grundlegende Beschreibungen, die deutlich ausführlicher sind, als unser kurzer Text. Lernen Sie die Grundlagen Neuronaler Netze und deep learning und erfahren Sie mehr über Convolutional Neural Networks.